
175 mil millones de parámetros y un planeta pinball imposible de entender
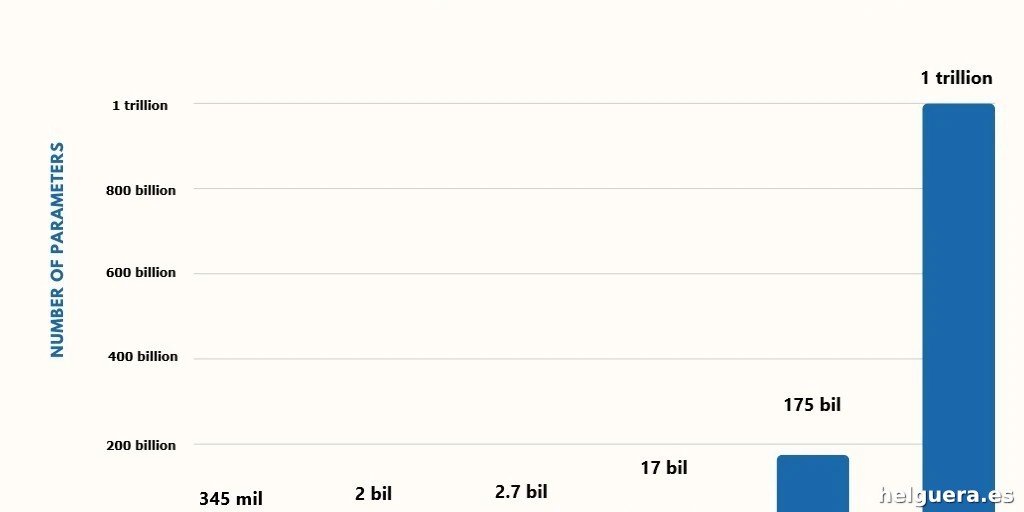
GPT-3 apareció en 2020 con unos estruendosos 175 mil millones de parámetros. Suena a pepino, ¿verdad? Pero espera, porque Google DeepMind anda sacando pecho con Gemini 3, que se rumorea que tiene desde 1 hasta 7 **trillones** de parámetros, aunque la compañía tiene el pico cerrado y no suelta prenda. La cosa es que esas cifras astronómicas no son sólo para impresionar en las fiestas (te lo juro), sino que son el núcleo de cómo funcionan los modelos de lenguaje a gran escala (LLM).
Imagina un pinball planetario, donde cada parámetro sería un péndulo, una palanca, una bumpers desquiciado que dirige esas pelotas locas de información. Cambia el ajuste de esos parámetros y el maldito pinball se comporta diferente. Esa poca broma matemática —un ballet frenético y caótico de números— es la esencia que hace que GPT y sus primos hablen, escriban, razonen y manchen pantallas con respuestas. Pero… ¿qué demonios es un “parámetro”?
Un poco de álgebra y magia algorítmica para entender los parámetros
No me mires con cara de póker, que es sencillo. Recuerda el colegio, cuando te tocaba con dos letras las ecuaciones tipo 2a + b. Esas letras, a y b, representan parámetros —valores que cambian la salida de la función. En un LLM, un parámetro es algo matemático que almacena un valor que afecta el resultado final. Pero no estamos hablando de un par de letras, sino de **billones** de parámetros, cada uno con su valor propio, afinado para hacer que el modelo funcione con sentido y no diga burradas.
¿Cómo consiguen esos valores? Con entrenamiento. Se asignan al principio valores aleatorios. A partir de ahí, viene la odisea del “ajuste fino”: el algoritmo mira cada error, ajusta parámetros para que el siguiente intento sea mejor y repite esto millones y millones de veces. En GPT-3, cada parámetro se actualizó decenas de miles de veces durante el entrenamiento, acumulando nada menos que cuadrillones (15 ceros) de cálculos. La energía para mover todo este tinglado es brutal: cientos de ordenadores especializados zumbando sin parar durante meses.
Sí, es caro y consume más energía que para sostener un país pequeño. Pero sin estos parámetros no habría nada que aprender ni que procesar.
Embeddings: el alma matemática de las palabras
¿Has escuchado eso del “embedding” y no tienes ni idea? Aquí va: un embedding es el modo en que un LLM traduce cada palabra o fragmento (token) a una especie de código numérico. No es un número único, ni dos… sino una lista larguísima de números. GPT suele usar listas de 4,096 números por palabra (“dimensiones”). ¿Por qué 4,096? Porque esque las computadoras y chips digitales miman las potencias de dos: 2, 4, 8, 16, 32 y así hasta que 4,096 pinta bien para eficiencia y capacidad.
Esos números (dimensiones) representan las mil y una sutiles relaciones y significados extraídas del océano de texto con el que el modelo se entrenó, un espacio matemático tan complejo que corresponde a una dimensión mutante y casi imposible de visualizar.
Cada palabra está en una especie de nube de puntos flotantes en 4,096 dimensiones, y la cercanía de los puntos revela significados similares. Por ejemplo, “mesa” y “silla” estarán pegaditos, mientras que “astronauta” se separa del lado de “músculo” y se acerca a “luna” o “Musk”. Y no, no puedes imaginarlo claramente, a menos que te guste marearte.
Con GPT-4.5, que algunos estiman con más de 10 trillones de parámetros, el modelo puede detectar matices como emociones ocultas en la conversación humana, gracias a esas embeddings tan ricas que codifican miles de capas de contexto emocional y semántico.
Pesos y sesgos: maestros del contexto y las conexiones invisibles
Si ya entendiste que las embeddings son “qué significa la palabra”, los pesos son “qué nos importa de esa palabra cuando la ponemos en contexto”. Los pesos definen la fuerza con la que una palabra afecta a otra en la cadena del texto, en la famosa red neuronal y sus transformadores (las capas que procesan todo a la vez).
Pero hay más: los sesgos (biases) no multiplican sino que suman, ajustando el umbral en que las neuronas virtuales se ‘disparan’ y activan otras. Es como si metieras un ruido de fondo para captar señales bajitas o “información perdida” en medio de todo el ruido de datos.
Piénsalo como en una fiesta ruidosa: los pesos hacen que oigas más fuerte a los que gritan, los sesgos hacen que escuches a los que hablan bajito también, para no perder detalle. Es el equilibrio sutil que garantiza que el modelo no se pierda en lo obvio y pueda sacar chispa de lo sutil.
Neuronas: una estructura caótica, no biológica, que hypea todo el sistema
Las neuronas en una red neuronal no son células reales, así que olvídate de imágenes de cerebros palpitantes. Más bien, son “nodos” organizadores que contienen esos pesos y sesgos y forman capas. Imagina una multitud de neuronas virtuales que se conectan unas con otras, formando un entramado monstruoso.
GPT-3, con sus 175 mil millones de parámetros, se extiende a lo largo de aproximadamente 100 capas, y cada capa tiene decenas de miles de neuronas que ejecutan decenas de miles de operaciones al segundo. Para cada dimensión de embedding (4,096), cada neurona mantiene un peso y un sesgo. El resultado de todo este sistema es la capacidad para procesar y producir texto altamente complejo y matizado.
Con cada ‘paso’ o capa que atraviesan los datos en forma de embeddings se ajustan una y otra vez las cifras (pesos y sesgos) hasta que se alcanza la versión “final” que se usa para decidir qué palabra viene a continuación. Más de eso en la siguiente sección.
¿Cómo narices decide qué palabra sale? La odisea del siguiente token
La teoría es sencilla: para cada fragmento de texto que le metemos, el LLM calcula numéricamente la probabilidad de que cada palabra del diccionario aparezca a continuación. No elige a ciegas, sino que establece un ranking desde la más probable a la menos probable.
En sí, elegir el siguiente token es una cuestión estadística enriquecida por toda esta maraña de parámetros. Pero atención, no siempre va a la segura con la más probable. Aquí entra el juego de los llamados *hiperparámetros* como temperatura, top-p y top-k.
La temperatura es la perilla que regula la creatividad. Temperaturitas bajas hacen que el modelo sea más conservador (elige fortalezas claras), temperaturas altas le meten la chispa de la imprevisibilidad y creatividad (elige opciones menos probables). Top-p y top-k limitan el pool de palabras candidatas y permiten que el modelo “mede” mejor sus opciones.
Este ajuste fino entre coherencia y sorpresa es la esencia de por qué una respuesta puede sonar humana, divertida, precisa o rara.
El boom de modelos pequeños que se comen a los grandes (y sin tragar tanto giga de datos)
¿Te molan los números grandes? Pues cuidado, porque la competencia dice «no solo importa el tamaño, sino cómo lo usas». Meta lo sabe bien: Llama 2 tiene 70 mil millones de parámetros, Llama 3 sólo 8 mil millones. Pero ojo, Llama 3 ha sido entrenado con más palabras (15 trillones vs 2 trillones de Llama 2). Resultado: la versión mini es la que da pie al parche.
¿Cómo puede un modelo pequeño pintar la cara a un gigante? Tres razones afiladas:
– Más datos de entrenamiento, suficiente para llenar y exprimir los parámetros que tiene.
– Overtraining, ese chollo de cargar al modelo con *más* datos de lo necesario para que saque mejores patrones.
– Lo más bestia: destilación, que no es literal con botellas, sino que un modelo grande le pasa sus trucos al pequeño, dejándole digerido el conocimiento para que se ponga las pilas rápidamente.
Además, esta era de modelos monolíticos como castillos inexpugnables parece estar dando paso al “mixture of experts” (mezcla de expertos). Grandes modelos que funcionan como un disfraz de varios pequeños modelos; se encienden sólo los módulos necesarios para una tarea, logrando buena potencia sin despeinarse en consumo y velocidad.
Entonces, ¿qué diablos es un parámetro y para qué sirve realmente?
Un parámetro es un simple número, sí, pero multiplicado por el número enloquecido de billones se convierte en la palanca detrás del poder loco de los LLM. Son la esencia de cómo esos modelos gigantescos aprenden, recuerdan, y entienden relaciones en datos. No son mágicos, solo mucha matemática aplicada y toneladas de computación.
Pero ojo, su número no lo es todo. Con la saturación del rendimiento por tamaño, la frontera está en qué hacemos con esos parámetros —su entrenamiento, su especialización, su fine-tuning— y cómo los combinamos en arquitecturas innovadoras.
Así que la próxima vez que alguien te lance un número gigante de parámetros, no te quedes en la impresión fácil. Pégate a las pieles de lo que esos números hacen, a la brutal mecánica que explica lo que vemos y oímos de los GPT, Gemini y hermanos. Y luego sigue cuestionando. Porque precisamente en un pinball tan enorme, el truco está en controlar esas palancas, no en el número.
¿A ti qué te parece? ¿Cuánto paramétrica poca chicha seguirá siendo suficiente en esta carrera?
Artículos Relacionados
Using unstructured data to fuel enterprise AI success
Más información sobre Apple prepara una cámara
Descubre the download: war in europe, and the company that wants to cool the planet